在 NVIDIA 幾乎壟斷 AI 算力的這幾年,Cerebras 是最受矚目的挑戰者之一。它在 2026 年 5 月上市,首日股價暴漲 68%,市場用真金白銀,肯定了這個挑戰者。
這是一家怎樣的公司,它的產品在實戰上能打到什麼程度,技術突破在哪裡,隱憂又在哪裡。
如果把 12 吋晶圓,不切割,直接做成一顆超大晶片呢?
Cerebras Systems 成立於 2016 年 3 月,總部在加州 Sunnyvale,由 Andrew Feldman 等五人創辦。它的核心理念,用一句話講完,就是不要把晶圓切成很多小晶片,而是把一整片十二吋晶圓,做成單獨一顆巨大的晶片。
這違反了半導體業最基本的成本邏輯。一般晶片受限於曝光機一次能成像的面積(業界稱光罩極限),單顆上限大約 800 平方公釐;Cerebras 的晶圓級引擎(Wafer-Scale Engine)邊長 21.5 公分、面積 46,225 平方公釐,等於把這個上限直接跳過,靠特殊製程把整片晶圓上的電路連起來。
它的作法是:曝光機照常一格一格曝,但連平常用來切割、原本會被丟掉的「切割道」也一起曝上連接線路,最後整片不切,就變成一顆晶片。所以突破點不在曝光技術,而在「連道路都曝、然後不切」這個特殊製程。

晶圓本身是圓的,這顆晶片卻是方的:它取的是一片標準 300 公釐圓形晶圓上,能切出的最大正方形,幾乎用滿一整片晶圓。
最新一代 WSE-3(搭配 CS-3 系統)採用台積電 5 奈米製程,內含 4 兆個電晶體、90 萬個 AI 核心、直接整合在晶片上的 44 GB SRAM,記憶體頻寬達 21 PB/s。整片晶圓做成一顆,最大的好處是核心之間的資料不用再透過晶片外的線路傳輸,延遲與頻寬瓶頸幾乎被消滅。
在矽晶圓常見的良率問題上,一般晶片因為面積小、數量多,只要有瑕疵就捨棄不用;但 Cerebras 這種超大面積晶片,採用的解法是預留冗餘核心,硬體偵測到瑕疵就自動繞開、維持功能。
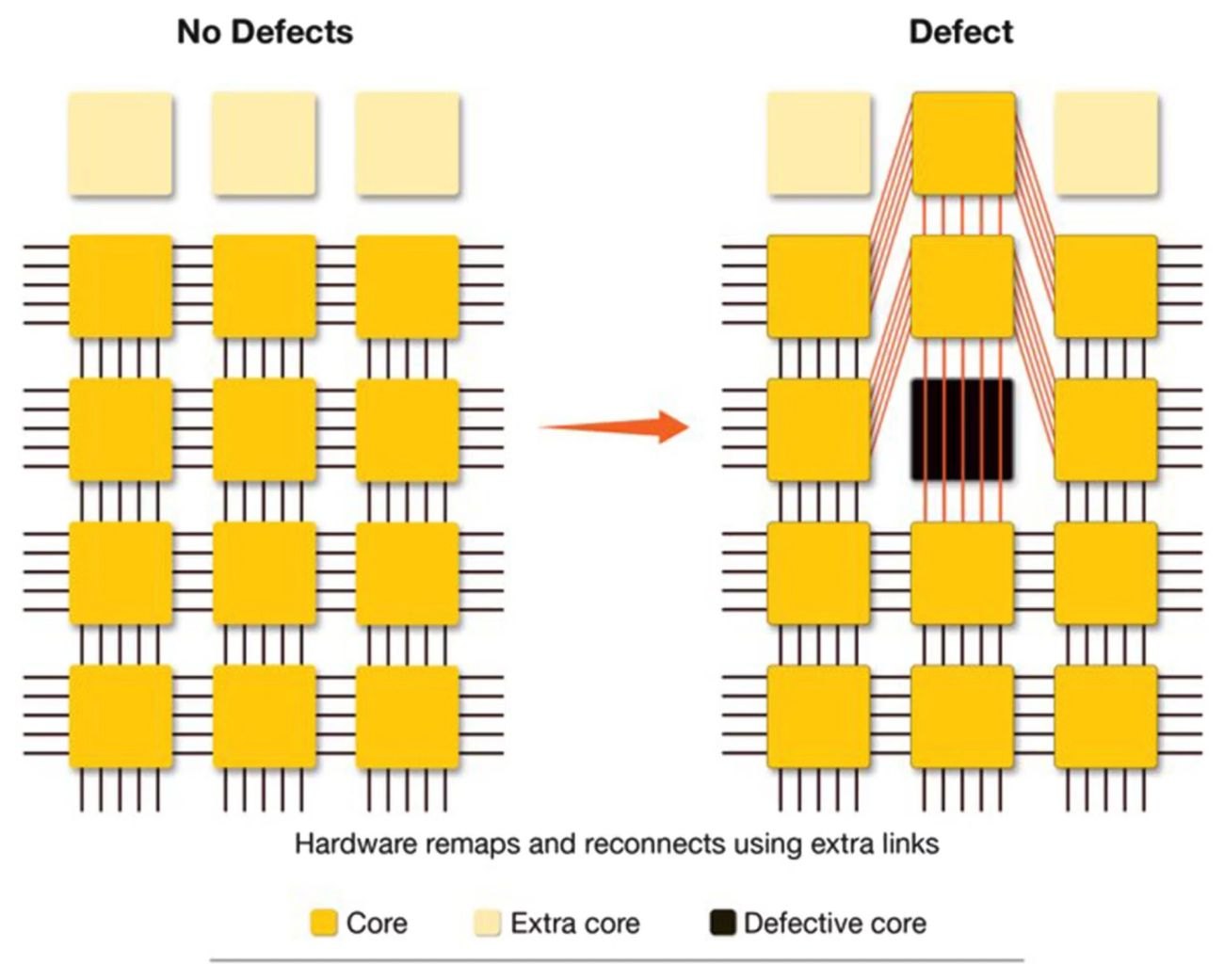
註:上述規格多為 Cerebras 官方數據,經 IEEE Spectrum 等第三方轉述確認,但尚無中立第三方實測。
已經有產品了嗎?誰在用、多少錢,開發環境打得過 CUDA 嗎?
產品已經到第三代(CS-3)。它是一台機架式伺服器,16U 高(資料中心的機櫃以「U」為高度單位,1U 約 4.4 公分,16U 大約 70 公分高),重達數百公斤,單台功耗約 23 kW,採客製化內循環水冷。這種熱密度,一般機房放不下,必須要有高密度供電與強力液冷的資料中心才能部署。

誰在用:
- 雲端與 AI:OpenAI 簽下多年算力合約(下面談上市與隱憂時會詳述);2026 年 3 月起與 AWS 合作。這個合作常被誤解為「把 CS-3 丟進 AWS 機房出租」,其實不是:依 AWS 官方公告,是在 Amazon Bedrock 上的「拆解式推論」,Trainium 做前段、CS-3 做後段,只做推論、不碰訓練。
- 主權 AI:G42 是阿聯酋阿布達比的國家級 AI 集團,旗下有雲端、模型、醫療 AI 等實際營運單位,不是純持股公司;由阿聯酋國家安全顧問 Tahnoun bin Zayed Al Nahyan 擔任主席兼控股股東,背後有國家主權基金 Mubadala,微軟也在 2024 年投資它 15 億美元,政府與國安色彩很濃。它串聯數十台 CS 系統,打造「Condor Galaxy」超級電腦。這個客戶後面談隱憂時還會再出現。
- 研究與製藥:美國阿貢、勞倫斯利佛摩等國家實驗室;GSK 與 AstraZeneca(曾把一項訓練從兩週縮短到兩天)。
價格與效果:整套系統售價在數百萬美元等級,再加上 MemoryX(存放模型權重用的外接記憶體單元)等元件後更高;但 Cerebras 主推的其實是雲端按量計費的推論服務。推論速度方面,官方數據在大模型上可達每秒 1,800 到 2,600 個字元(token)。它發表初期宣稱比 NVIDIA GPU 雲端方案快約 20 倍,後續自家更新仍宣稱領先一個數量級(某次數據是比最快的 GPU 方案快約 16 倍)。要提醒的是,這些都是 Cerebras 自家測試,目前沒有中立第三方的跨廠 benchmark。
打不贏 NVIDIA 的軟體生態,那就讓開發者不需要它
NVIDIA 真正的護城河,是一套叫 CUDA 的開發軟體。幾乎全世界的 AI 工程師都是用它訓練出來的、用習慣了,要大家換掉非常難。Cerebras 沒有正面去搶這塊,它走的是另一條路:讓工程師根本不必碰最麻煩的那一段。
打個比方。平常要訓練一個超大模型,工程師得自己想辦法把模型「切成很多塊」,分散到成百上千張晶片上跑,還要盯著這些晶片之間怎麼互相協調,這是出了名的繁瑣又容易出錯。Cerebras 的運算是一整片晶圓,模型權重放在外接的那組記憶體裡,軟體把整套硬體包裝成「單一一台機器」呈現給開發者:你就當成有一台記憶體大到塞得下整個模型的電腦在寫,不必去管底下其實是晶圓和外接記憶體在分工。工程師照樣用原本熟悉的開發工具(PyTorch)寫程式,切分和協調都交給系統自動處理。對寫程式的人來說,等於把最痛的那段直接省掉了。
股票上市了嗎?市場反應如何?
Cerebras 在 2026 年 5 月 14 日正式於 Nasdaq 掛牌,股票代號 CBRS。據 CNBC 與 SiliconANGLE:發行價每股 185 美元,售出 3,000 萬股,募得約 55.5 億美元;開盤跳到 350 美元,收盤 311.07 美元,首日大漲 68%。
目前市值,Motley Fool 以完全稀釋計算約 564 億美元,CNBC 則以收盤市值計算約 950 億美元。差別在「稀釋與非稀釋」的計算基礎不同:非稀釋只算現在實際在市場上流通的股票;完全稀釋還會把員工尚未行使的選擇權、認股權證這些「未來可能變成股票」的部分一起算進總股數。再加上兩家取的股價時點不同,得出的市值自然不一樣。
此前 IPO 一度卡關,原因是美國外國投資委員會(CFIUS)要審查 G42 的持股;後來 G42 把股權改成無投票權,2026 年 4 月才重新遞件,5 月成功掛牌。

Cerebras 如此強勁,未來有什麼隱憂嗎?
首日暴漲 68% 很熱鬧,但招股書(S-1)裡的東西冷靜得多。以下六點,來自 S-1 拆解分析。
一、客戶集中度極端高
2025 年營收的 86%,集中在兩個阿聯酋客戶身上:G42 與 MBZUAI。G42 就是前面介紹過的那家阿聯酋政府色彩濃厚的 AI 集團,MBZUAI 則是當地的人工智慧大學。兩者合計 86%(其中 MBZUAI 占 62%、G42 占 24%)。未來營收則高度押注在 OpenAI 這個新大客戶身上,等於從一個集中風險,換到另一個集中風險。
二、地緣政治與出口管制
這裡有兩件事要分開講。第一,G42 帶有阿聯酋主權與國安體系的背景,這種中東主權色彩的大客戶兼股東,曾引發美國外國投資委員會(CFIUS)的國安審查,也正是 Cerebras 上市一度卡關的原因。第二,Cerebras 自己的美國本土客戶營收,2025 年大幅下滑 34%(從 2.83 億美元掉到 1.88 億美元),等於它的成長越來越靠海外、尤其是靠中東客戶撐著。萬一美國政府收緊高階 AI 晶片輸往中東的出口管制(這類限制已經用在中國身上,中東也被討論過),Cerebras 的營收支柱可能遭到毀滅性打擊。
三、扣掉一次性收益,本業其實在虧
先解釋兩個會計名詞。GAAP 是美國公認會計準則,也就是財報「照官方規定」算出來的數字;公司通常還會附一個 Non-GAAP 版本,把一次性、不會年年發生的項目剔除,試著呈現「本業常態」長什麼樣。Cerebras 2025 年 GAAP 帳面是賺錢的,但這份獲利裡,包含一筆來自 G42 重組協議的 3.63 億美元一次性非現金收益。把這種「今年有、明年不會再有」的項目拿掉,本業其實是淨損約 7,570 萬美元。換句話說,單靠賣晶片這件事本身,它還沒真正賺到錢。
四、產能命脈,全壓在台積電
WSE-3 用台積電 5 奈米,而且一顆晶片就吃掉一整片晶圓,晶圓消耗量極大。它手上有高達 246 億美元、客戶已經下單但還沒交貨的訂單(也就是「訂單積壓」,主要來自 OpenAI),代表外面要跟它買的需求很猛;問題是要把這些訂單真的做出來,得跟台積電搶產能,而它在這件事上的議價籌碼,比 NVIDIA 弱得多。
五、公司治理與執行長的前科
招股書也自承財務報告的內部控制有重大缺失(material weakness)。更微妙的是執行長 Andrew Feldman 的一段往事:他二十多年前在 Riverstone Networks 任職期間,公司涉及以私下協議灌水營收的會計舞弊,遭美國證管會(SEC)起訴,Feldman 為此付出代價(含繳回不當所得、刑事認罪)。這不是新聞標題會放大的事,但白紙黑字寫在 Cerebras 招股書的風險因子裡。
六、雙層股權與解禁賣壓
它採「雙層股權」結構:股票分兩種,一般投資人在市場上買到的是普通股、一股一票;創辦人與內部人手上則是 Class B 股,每股有 20 票投票權。結果就是,就算外部股東出了大部分的錢、持有大量股份,公司的控制權還是牢牢握在內部人手裡。加上部分早期股東的閉鎖期(上市後一段時間內不能賣)一旦到期,未來有潛在的解禁賣壓。
技術很猛、IPO 很猛,但這是一家「靠一個中東客戶撐起八成營收、本業還在虧、命脈綁在台積電、執行長有前科」的公司。看好它的技術,跟把它當穩健投資,是兩件不同的事。
缺算力的 Anthropic,為什麼不找它合作?
幾個結構性原因。
- 已被巨頭排他綁定。Anthropic 兩大金主是 Amazon 與 Google。據 Axios,Amazon 已投資 Anthropic 50 億美元、並握有最高再加碼 200 億美元的選項,另有商業協議讓 Anthropic 砸下約 1,000 億美元、最高 5GW 的 AWS 算力;Google 則最高投資 400 億美元(先投 100 億、估值 3,500 億美元,另 300 億視里程碑達標),同樣綁定 5GW 的 Google Cloud 與 TPU。兩邊都把算力綁死在自家雲,沒有空間大舉採購 Cerebras。
- 真正的瓶頸是電力,不是晶片。2026 年的 AI 限制因素是電網供電。Anthropic 傾向直接找「手上有電、有資料中心」的對象:例如它在 2026 年 5 月租下 Colossus 1(超過 300MW、逾 22 萬顆 GPU;這座資料中心原屬 xAI,xAI 併入 SpaceX 後成其資產),而不是再去整合一套高耗電的新硬體。
- 產能被 OpenAI 先卡位。OpenAI 已先簽下 Cerebras 大量產能與雲端容量,Anthropic 想拿也難。據 OpenAI 官方與 The Next Platform,這紙合約 2026 年 1 月 14 日公布,基礎規模超過 100 億美元、750MW 推論算力(後續報導擴大到逾 200 億美元),OpenAI 另提供 10 億美元、利率 6% 的營運資金貸款,以及最多約 10% 至 11% 的無投票權認股權證。
- 模型架構適配成本高。Cerebras 軟體目前對結構公開的開源模型優化最好,要把 Anthropic 高度保密的模型搬上去,深度底層整合的時間成本太高。
用算力電力比來看,Cerebras 跟 NVIDIA 到底誰划算?
先講純理論峰值,再講為什麼帳面數字會騙人。
註:能效比是以上述功耗與算力換算(PetaFLOPs ÷ kW),非廠商直接公布的數字。
但帳面數字會騙人,原因有二:
- 大規模叢集的隱形損耗。NVIDIA 大規模串聯時,網路交換器、光纖模組很耗電,GPU 等待通訊時也有閒置功耗,整體有效能效會衰減。Cerebras 核心通訊在晶圓內部,這塊損耗較小,但這同樣是它官方的宣稱。
- 熱密度是致命傷。我們前面拿來比的那一代 NVIDIA(DGX H100),一般機房用風扇吹、風冷就能應付(不過 NVIDIA 最新的 Blackwell 整櫃系統也已改成液冷)。Cerebras 沒有這個選項:23 kW 的熱量全壓在一張 21 公分見方的晶圓上,熱密度極高,必須配上精密的高壓客製水冷。更麻煩的是,因為它是「整片晶圓做成一顆」,散熱只要某一處出狀況,壞掉的不是其中一顆可以單獨抽換的晶片,而是有可能傷到整片晶圓,這是單片架構天生的脆弱面。蓋這種局部超高密度供電加散熱的基礎設施,成本也會吃掉它在電費上省下來的一部分優勢。
理論峰值 Cerebras 確實漂亮,但「省電」是系統層級的總帳,不是看單台 spec。真實工作負載、散熱基建折舊算進去,差距會收斂。這也是為什麼能效比這種數字,要永遠記得它是廠商給的。
那 NVIDIA 自己,有沒有在走「大尺寸整合」這條路?
有,但 NVIDIA 走的是「先進封裝把多顆拼成一顆」,而不是 Cerebras 那種「整片晶圓做一顆」。
- 第一步:雙晶片合體。B200 由兩顆達光罩尺寸極限的晶粒,透過台積電 CoWoS-L 封裝放在同一個中介層上,晶粒間互連達 10 TB/s,軟體上表現得像一顆超大晶片。
- 第二步:整櫃當成一顆。再往上一層,GB200/GB300 NVL72 用第五代 NVLink 這種超高速銅線背板,把整櫃 72 顆 GPU 綁在一起,在軟體上被當成「一顆超級 GPU」操作。這些連線整櫃加總起來的傳輸速度約 130 TB/s(對照一下,上面第一步兩顆晶粒之間是 10 TB/s,這裡又快了一個量級),快到 72 顆 GPU 之間搬資料幾乎不會卡,所以才能被當成一顆來用。
- 下一代 Rubin:延續同一套路,用更先進的封裝把多顆晶粒和記憶體疊在一起,走的還是「把很多顆拼成一顆」這條路,不是 Cerebras 那種整片晶圓。坊間有「Rubin 會改走整片晶圓」的傳聞,但目前沒有可靠來源佐證。
商業邏輯的差異很清楚:NVIDIA 選擇「小晶片先進封裝 → 機櫃互連」,是為了保住良率、100% 繼承 CUDA 生態,以及維持從單卡到整櫃的產品線彈性,買多買少都可以,升級降級很容易。Cerebras 則選了一條沒有退路、但延遲與頻寬天生贏的路。這是兩種完全不同的賭注。
